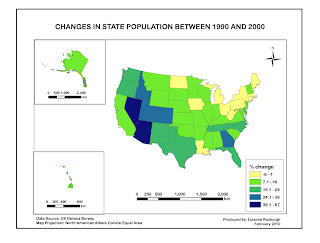
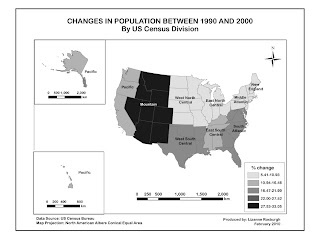
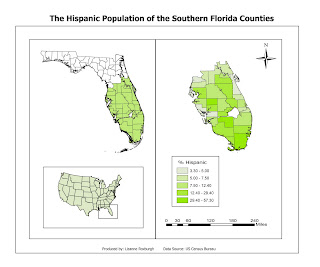
Our assignment for this week was to map the percentage of African Americans living in different parts of Escambia County, Florida, using different data classification methods, and to assess which classification method best represents the data.

Which classification best represents the data and why?
The data are positively skewed. Thus using the Equal Interval classification is not ideal, as most counties fall into the first two classes, with the last class having very few counties.
The distribution of data across Natural Break classes is also clumped, again with the first two classes containing most of the data. This would be the method of classification that I would probably avoid in general as it is not easily interpretable and is difficult to compare between maps.
Both Standard Deviation and Quantile classifications produce a more even distribution of data as there are approximately equal number of counties in each class. However, as the data are positively skewed, and thus not normally distributed, the Standard Deviation method would be best used if the data were normalized first.
I would thus choose the Quantile method as the best method of representation for this data set.